Menos Infraestructura, Más Valor: Repensando la Arquitectura RAG en .NET
Si siguen este blog, saben que aquí no nos quedamos en el «Hola Mundo». Nos gusta hablar de arquitectura y de las decisiones difíciles que hay detrás del código. Hoy vamos a analizar una herramienta que nos plantea un dilema interesante sobre la complejidad accidental en nuestros proyectos de IA.
El panorama real de .NET y la IA
Primero, pongamos los puntos sobre las íes. Existe el mito de que .NET está «atrás» en Inteligencia Artificial. Si hablamos de entrenamiento de modelos y ciencia de datos pura, es cierto: Python es el rey.
Pero cuando hablamos de Ingeniería de IA, Orquestación y Agentes, la historia es diferente. Con herramientas como Semantic Kernel y el Microsoft Agent Framework, el ecosistema .NET está al nivel de los mejores. Tenemos la capacidad de construir sistemas robustos. La pregunta es: ¿siempre necesitamos construir el sistema completo?
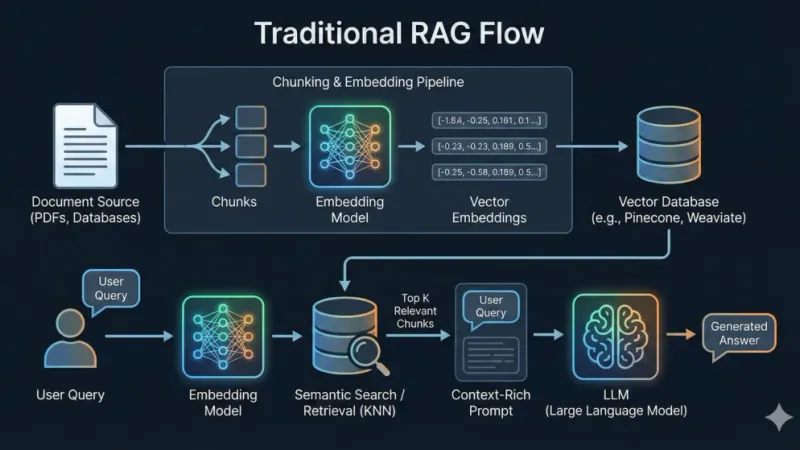
El costo oculto del RAG «Artesanal»
Implementar RAG (Retrieval-Augmented Generation) en producción es mucho más que enviar un prompt. Si decides hacerlo «a mano», asumes la carga de una infraestructura compleja:
- Chunking: Decidir cómo trocear la información.
- Embeddings: Generar y actualizar los vectores.
- Vector Store: Mantener una base de datos (Pinecone, Qdrant) y pagar por ella.
A menudo terminamos con una arquitectura pesada solo para funcionalidades sencillas.
La Alternativa Pragmática: Gemini File Search
Aquí entra Gemini File Search. Véanlo no como una librería más, sino como una decisión de arquitectura: Serverless RAG. Delegamos la gestión del índice y la recuperación a Google, convirtiendo un problema de infraestructura en una simple llamada de API.
El Negocio manda: Privacidad vs. Comodidad
Antes de emocionarnos con la facilidad técnica, hay que pasar por el filtro más importante: La realidad del negocio.
En escenarios reales, las decisiones de arquitectura no siempre se basan en qué tecnología es más fácil de usar o cuál tiene mejor chunking. A menudo, la decisión la dicta el departamento legal o de seguridad.
Si trabajas en banca, salud o gobierno, subir documentos sensibles a un almacenamiento gestionado por un tercero (como el File Store de Gemini) puede ser inviable por regulaciones de privacidad.
Seamos claros: subir contratos confidenciales de tu empresa o datos personales de clientes a una nube pública sin permiso es probablemente la forma más rápida que existe de actualizar tu estado en LinkedIn a «Open to Work». 😅
En esos casos, donde los datos no pueden salir del perímetro, la comodidad de la API de Google pasa a segundo plano y estás obligado a montar tu propia infraestructura (un RAG artesanal on-premise o un Azure AI Search aislado en una VNET), no por gusto técnico, sino por obligación.
La Regla de Oro: Entender antes de Abstraer
Dicho lo anterior, si el negocio lo permite y decides usar esta herramienta, no lo hagas a ciegas.
Lo que nos define como ingenieros es entender qué estamos abstrayendo.
- El Chunking es crítico.
- La estrategia de recuperación define la calidad de la respuesta.
Esto aplica para todo: si usas Gemini File Search, aceptas que Google decida esto por ti (caja negra). Pero incluso si usas herramientas más controladas como Azure AI Search, de nada sirve tener 100 opciones de configuración si no entiendes los fundamentos del RAG.
Un mal arquitecto usa Gemini porque «es fácil». Un buen arquitecto lo usa porque evaluó privacidad, control y costos, y decidió que era la pieza correcta para el rompecabezas.
La Evidencia: Simplicidad en Código
Si has validado los requisitos de privacidad y técnicos, fíjate en la limpieza que logramos en el backend. Todo el ciclo de vida se reduce a unas pocas líneas
NOTA: Este no mejor código, se omiten validaciones, es solo de referencia y no debe usarse para producción así.
using System;using System.Collections.Generic;using System.IO;using System.Linq;using System.Threading.Tasks;using Mscc.GenerativeAI;
var apiKey = "TU_KEY_GEMINI_CLOUD";var filePath = "ejemplo_instalacion.txt";var question = "¿Cuáles son los requisitos de instalación según este documento?";
var googleAi = new GoogleAI(apiKey!);var model = googleAi.GenerativeModel(Model.Gemini25Flash);var fileSearchStores = googleAi.FileSearchStoresModel();
// Aquí se crea el storagevar store = await fileSearchStores.Create(new FileSearchStore { DisplayName = "demo-store" });var uploadResponse = await googleAi.UploadFile(filePath, Path.GetFileName(filePath));var fileResource = uploadResponse.File!;while (fileResource.State == StateFileResource.Processing){ await Task.Delay(TimeSpan.FromSeconds(2)); fileResource = await googleAi.GetFile(fileResource.Name);}
// Aquí se agrega el archivoawait fileSearchStores.ImportFile(store.Name!, fileResource);while (true){ var current = await fileSearchStores.Get(store.Name!); if ((current.PendingDocumentsCount ?? 0) == 0) { break; }
await Task.Delay(TimeSpan.FromSeconds(2));}
// Aquí se hace la consultavar request = new GenerateContentRequest{ Contents = [ new() { Role = Role.User, Parts = [new TextData { Text = question }] } ], Tools = [ new Tool { FileSearch = new FileSearch { FileSearchStoreNames = [store.Name!] } } ]};
var response = await model.GenerateContent(request);
Console.WriteLine($"Pregunta: {question}", question);Console.WriteLine($"Respuesta: {response.Text?.Trim() ?? "(sin texto)"}");¿Vieron lo limpio que quedó el código? Eso sí, siempre recordando que ya hicimos la tarea previa de evaluar si esto es lo que el negocio necesita. Pero fíjense en un detalle clave: no estamos usando una API especial ni un modelo distinto. Es la misma API de Gemini de toda la vida. Lo único que hacemos es avisarle que tiene una Tool (herramienta) nueva disponible. El modelo sigue siendo el mismo, pero ahora tiene la capacidad de consultar esos documentos por su cuenta si lo necesita. Nos ahorramos todo el «pasamanos» de traer los datos y pegarlos en el prompt manualmente.
Si alguna vez sufrieron manteniendo un RAG artesanal, saben que quitarse ese dolor de cabeza no tiene precio.
Conclusión
Gemini File Search es una herramienta poderosa para eliminar deuda técnica en MVPs y aplicaciones de uso general. Pero no es una excusa para ignorar cómo funcionan los datos por debajo ni para saltarse las reglas del negocio.
Úsala cuando la agilidad sea la prioridad y la privacidad lo permita. Para todo lo demás, el ecosistema .NET tiene las herramientas para construir lo que necesites a medida.
Si quieres seguir aprendiendo sobre estos temas te invito a ver mis otras publicaciones.
